「我一个做识别的,怎么就来做分割了呢?」
RetinaNet 是一个用于目标检测的结构较为简单的深度网络。它是在 Focal Loss 的文章里顺便提出来的,可见 Focal Loss for Dense Object Detection。这篇文章本身是在讨论巨量候选框正负样本不平衡导致的 loss 失衡问题,不过本文主要是想借 RetinaNet 来初步地探索深度学习中的目标检测模型套路。
下文引用的代码来自一个 RetinaNet 的实现 ↗。
模型#
概览#
RetinaNet 是一个 one-stage 的 end-to-end 模型,意为该模型只有一步优化过程,目标的框选和分类一次完成,整个训练能够同时进行。与之相对的是一些两步甚至多步的方法,像是 R-CNN 等。
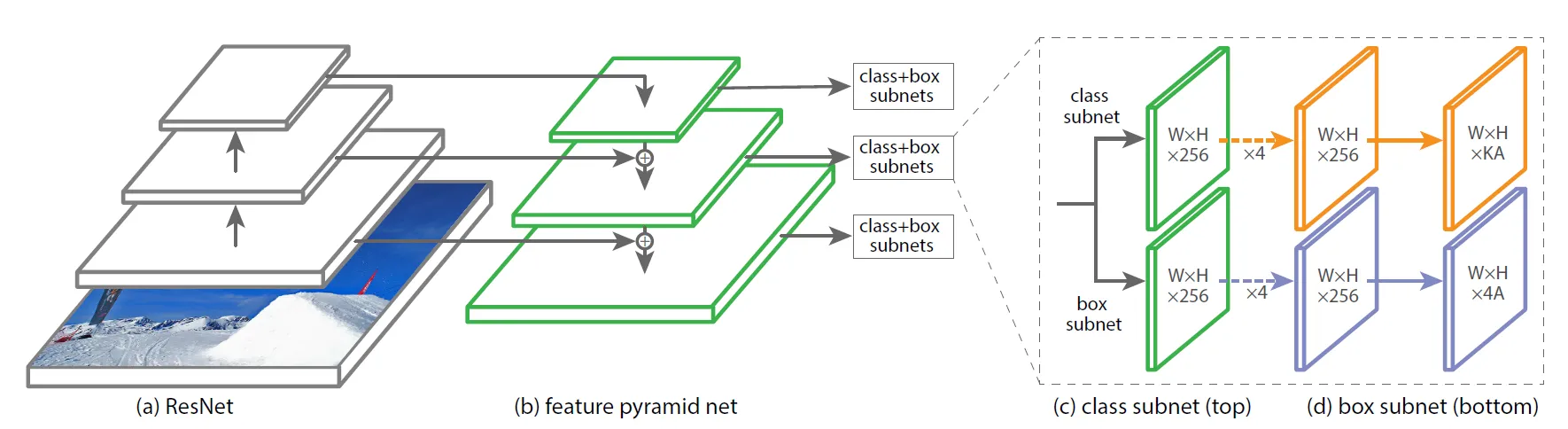
网络整体是 U-Net 的结构,在目标检测、分割中常见,即网络从低到高,再由高到低形成 U 型,再添加纵向连接来增强多尺度特征。RetinaNet 在主网络的不同尺度上接入两个头来分别预测目标类别及物体框。网络整体是极为简单的,没有什么花里胡哨的怪东西。模型输入就是图像。主要是输出格式,输出也暗示模型的设计思路。RetinaNet 对特征 每个像素输出 个框(bounding box,bbox),每个框输出 个类别的置信度和框的「坐标」。
网络使用了 ResNet-101 作为 backbone,从 stage 3、4、5 上分别导出图像特征。
RetinaNet 的图像分辨率为 1024,这意味着从上导出的特征分别是 、、。此后我们来到 U 型网络的另一侧,另一侧通过一系列的卷积和侧向连接,生成从 P3 到 P7 多个层级的特征。每个特征点都对应着原图中的一块区域。
Anchor#
朋友,我是说,接下来需要解释一下这个框的「坐标」。
如你所想,RetinaNet 所代表的一类方法(Anchor-based)中有一个特殊的概念:就是刚刚提到的 个框,称为锚框,英文为 Anchor。Anchor 并非指物体的 bbox,而是指为每个位置预设的数个不同大小(scale)、比例(ratio)的框。Anchor 的意义类似于传统检测算法中的滑动窗口,例如我们要从一张图像中匹配对应物体,一个直观的想法是枚举该图像中的所有位置,划出一个和待匹配物体大小一样的框,然后计算框中片段的特征是否和待匹配物体一致。这一部分在传统算法中可以直接描述为过程式的代码,但在深度网络里显然做不到,anchor 就是一个在深度网络里实现类似滑动窗口的机制。这就直观解释了 anchor-based 的工作都会在不同尺度的所有像素上预设了不同大小和比例的预选框。
以下是一份生成 anchor 的代码。其实没什么可看的,主要含义就是以 为中心,按照给出的缩放和比例生成不同大小的框,然后将框的形式变换成两个顶点的坐标 。
def generate_anchors(base_size=16, ratios=None, scales=None):
"""
Generate anchor (reference) windows by enumerating aspect ratios X
scales w.r.t. a reference window.
"""
if ratios is None:
ratios = np.array([0.5, 1, 2])
if scales is None:
scales = np.array([2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)])
num_anchors = len(ratios) * len(scales)
# initialize output anchors
anchors = np.zeros((num_anchors, 4))
# scale base_size
anchors[:, 2:] = base_size * np.tile(scales, (2, len(ratios))).T
# compute areas of anchors
areas = anchors[:, 2] * anchors[:, 3]
# correct for ratios
anchors[:, 2] = np.sqrt(areas / np.repeat(ratios, len(scales)))
anchors[:, 3] = anchors[:, 2] * np.repeat(ratios, len(scales))
# transform from (x_ctr, y_ctr, w, h) -> (x1, y1, x2, y2)
anchors[:, 0::2] -= np.tile(anchors[:, 2] * 0.5, (2, 1)).T
anchors[:, 1::2] -= np.tile(anchors[:, 3] * 0.5, (2, 1)).T
return anchorsRetinaNet 使用的缩放和比例分别是 和 ,也就是一个「位置」对应了 9 个框。在不同尺度上,按照更高层拥有更大视野的直观想法,我们定义不同大小的框在这些尺度上分别负责捕捉小物体和大物体。不同大小的 anchor 在当前尺度的每个特征点放置1,最终我们就在一张图上得到了大量的 anchor,这些 anchor 几乎可以覆盖所有的物体。
「几乎」。
回到模型#
刚刚说到 RetinaNet 在网络的不同层上接入了两个头来预测类别和框,现在我们看它具体是怎么做的。
分类头极其简单,就是大量 且 padding 为 1 的 CNN 的堆叠(这样卷积前后的图像大小是一样的)。最后输出定义为
class ClassificationModel(nn.Module):
def __init__(self, num_features_in, num_anchors=9, num_classes=80, prior=0.01, feature_size=256):
# ......
self.output = nn.Conv2d(feature_size, num_anchors * num_classes, kernel_size=3, padding=1)
self.output_act = nn.Sigmoid()也就是对每个特征点的 9 个 anchor 分别输出每个类别的置信度。上一节中说到,一张图像上的 anchor 几乎可以覆盖所有的物体,如果真的可以完全覆盖的话,到这里我们的任务就完成了,毕竟都有和 anchor 一一对应的类别置信度了。

然而现在就突发恶疾肯定要寄。
- 最小的框也有 32 像素长,也能占到全图横纵上有个 3% 的比例;而且再往上就成 64、128 了,但凡有个 48、100 的……
- 同一个物体可能会被多个框部分圈入。先不谈如何确定该把哪些 anchor 设置为包含当前物体,简单以正负来评价 anchor,没法拿到准确的 bbox,即使拿到,也需要转进第一个问题。
一个想法可能是大力扩增 anchor 的 ratio 和 scale。这自然是一个可行的办法,但也会增加网络的运算量,属于 trade-off,毕竟不计成本的话不如干脆滑动窗口加 CNN 来打天下。因此,我们还是需要合理数量的 anchor 配合网络额外的输出,这个输出要能赋予僵化的 anchor 一点人生经验,在 RetinaNet 里就是卷出来的 。
回到 Anchor#
模型输出的 bbox 并非绝对坐标,否则无论是从数值分布上还是对输入图像大小的普适上都会有问题。实际上,这部分输出的格式一般是 anchor 与预测 bbox 间的归一化差值。把 box 记为左上角坐标及其长宽,也就是 ,记 anchor 和 bbox(物体框)的坐标分别为 ,那么模型输出记为
RetinaNet 中 。我没搞明白为什么,这个看起来像是个调整数据分布的超参,暂且当个效果不错的 magic number 对待吧。
上文还遗留了一个问题,「如何确定该把哪些 anchor 设置为包含当前物体」。这就见仁见智了,RetinaNet 是按照交并比(Intersection over Union,IoU)来确定的2。IoU 如同其字面意思,
我们将与真实 bbox 重合大于 0.5 的 anchor 标记为正,小于 0.4 的标记为负,0.4 到 0.5 之间的忽略。
到这里,整个 RetinaNet 的结构就已经基本说明了。大量 anchor-based 方法的思路均类似,如果有机会之后会看看 yolo。
Loss#
我们都已经给出了类别和 bbox 了,loss 就是 BCE 和一些简单回归 loss 的组合了。RetinaNet 使用了其自己提出的 Focal Loss 与平滑 L1 loss 的组合。因为本文主要是想梳理目标检测的一种思路,所以不在此多费笔墨,具体可查阅论文。
Focal Loss#
实际上 Focal Loss 才是这篇论文的贡献。按照文中说法 RetinaNet 是一个大路边常见的简单网络,只是为了说明 Focal Loss 的优势。Focal Loss 主要是想解决正负样本失衡的问题,它的思路是把那些容易识别的种类在 loss 中降权。
假设输入为 ,网络输出为 ,地面真值ground truth 为 ,一般的 BCE 可以写作
用下面这个 稍微替换一下
也就是
Focal Loss 在这之上改了这么个东西
直观上的意义就是分类器越有信心的预测结果越会受到削弱。本文提出这个 loss 是为了解决大量负预测框(显然不包括任何物体的预测框占多数)把 loss 中的正样本带歪的问题,不过后续也有工作用它解决类别失衡,也取得一些效果。其他具有相同意义的 loss 同样取得了不错的效果。更多具体的实验还是去看论文吧。
Smooth L1 Loss#
就是平滑过的 l1 loss。
不太清楚这样设计的好处,我只能模模糊糊地讲 l2 loss 导数在 0 附近具有更好的性质,而 l1 loss 相比 l2 能够防止梯度的爆炸问题。更具体的还是参考 Fast R-CNN 一文吧。
*[bbox]: Bounding Box.