本文分为三部分:
- 第一部分为官网 Distributed Data Parallel 设计思路翻译;
- 第二部分为官网教程;
- 第三部分为实际使用时的一些笔记。
Distributed Data Parallel 设计笔记#
torch.nn.parallel.DistributedDataParallel(DDP)透明1地执行分布式数据并行训练。该部分内容解释了 DDP 的运行原理及设计细节。
例子#
我们先从一个简单的 torch.nn.parallel.DistributedDataParallel 例子开始。这个例子使用了线性层作为本地模型,使用 DDP 包装后,分别运行了一次前向传播、反向传播以及一步优化。之后,本地模型的参数将被更新,其他线程的所有模型均应保持一致。
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size):
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
optimizer.step()
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()内部设计#
这一部分阐述了 torch.nn.parallel.DistributedDataParallel 的运行原理,深入了一次迭代中所有步骤的细节。
- 预先准备: DDP 依赖于 c10d
ProcessGroup作为通信手段。所以在使用 DDP 前应用必须先创建ProcessGroup实例。 - 构建 DDP: DDP 构建需要本地模型的引用,而后会把在 rank 0 进程上的本地模型的
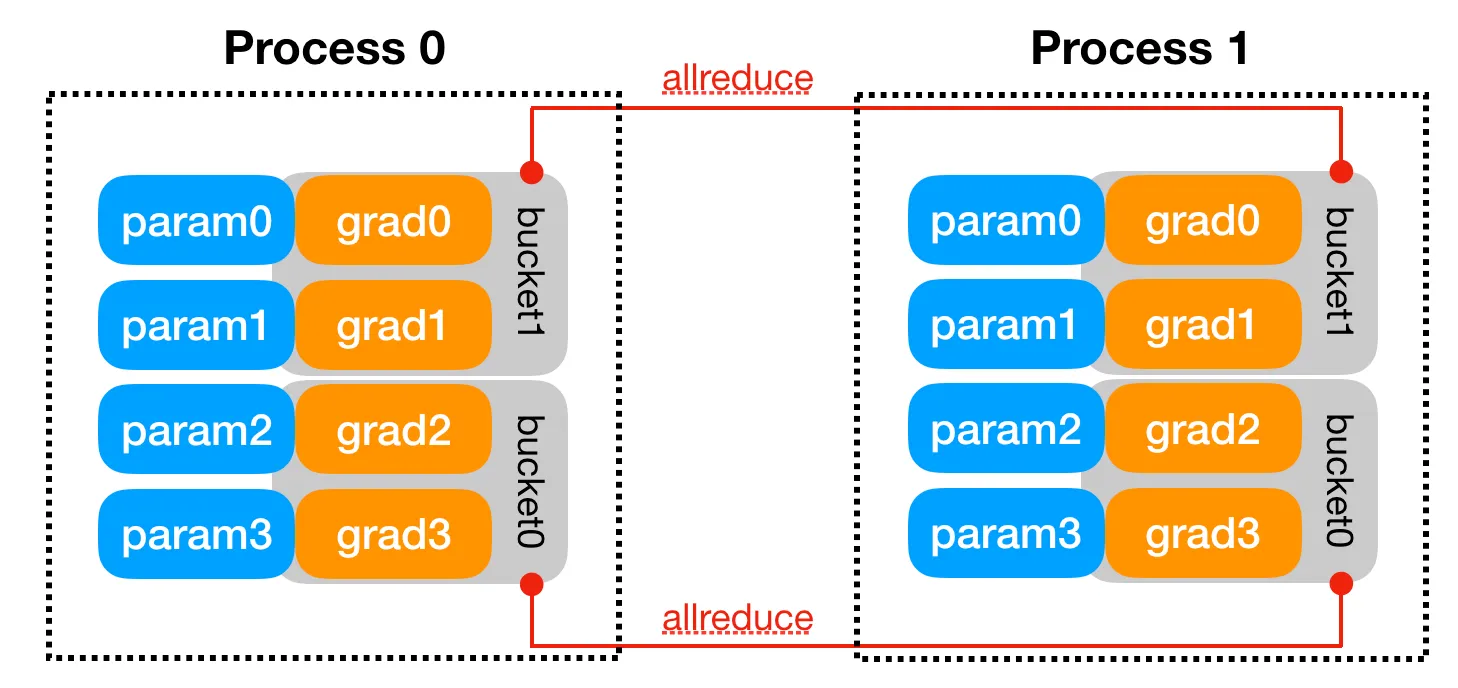
state_dict()广播到同组的其他进程,从而保证所有模型副本都从一致的状态开始训练。然后,每个 DDP 进程都会创建本地的Reducer,用于在反向传播阶段同步梯度信息。为了优化通信效率,Reducer将参数分成多个桶,每次仅处理一个桶。桶大小可以通过 DDP 的bucket_cap_mb参数调整。参数梯度到桶的映射是 DDP 在构造时根据桶大小和参数量确定的。模型参数大致上是按照Model.parameters()的逆向顺序保存到桶中的。这么做的原因是 DDP 希望梯度按照反向传播的顺序依次就绪。下图给出了一个简单的例子。注意grad0和grad1都在bucket1中,其他两个梯度则在bucket0中。当然,这个假设不会总符合实际情况。由于Reducer不能在尽可能早的时间启动数据通信,这种情况将会拖慢 DDP 的反向传播速度。除了桶,Reducer同样在构造时给每个参数注册了梯度钩子。这些狗子将会在反向传播过程中对应梯度就绪时触发。 - 前向传播: DDP 获取输入并将其传递给本地模型,如果
find_unused_parameters被设置为真,那么其还会分析本地模型的输出。这种方法允许我们仅在模型的一部分上反向传播,通过遍历模型输出的梯度图,将所有未使用参数标记为「就绪」状态,DDP 能够找出参与反向传播过程的参数。在反向传播过程,Reducer将只等待未就绪状态的参数,但仍将 reduce 所有的桶。将参数梯度标记为就绪现在并不能让 DDP 自动跳过对应桶,但能够防止 DDP 在反向传播过程中无限等待不存在的梯度数据。注意,遍历梯度图将带来额外的代价,所以没有必要时应用不应该设置find_unused_parameters。 - 反向传播:
backward()操作是在损失 Tensor 上执行的,这部分不在 DDP 的控制之下。DDP 使用梯度钩子来触发梯度同步。当一个梯度就绪后,它对应的 DDP 钩子也会被触发,DDP 就可以把参数梯度标记为就绪了。当一个桶中的所有梯度都就绪后,Reducer就会开始在桶上执行异步allreduce过程,来计算所有进程中该部分梯度的均值。当所有的桶都完成后,Reducer就会阻塞进程,等待所有allreduce完成操作。当所有步骤结束后,梯度均值将会被写回所有参数的params.grad。到目前,所有 DDP 进程中对应参数的梯度都应该是一样的。 - 优化: 从优化器的角度来看,它只会优化一个本地模型。不同 DDP 进程的模型副本都能保持同步,因为它们都从一个状态开始,并且每次优化迭代中它们的梯度都是一致的。
Distributed Data Parallel 入门#
DistributedDataParallel(DDP)实现了模块级别的数据并行,能够在多台机器上同步运行。使用 DDP 编写的应用会创建多个进程,并在每个进程创建 DDP 单例。DDP 使用 torch.distributed 包里的通信方法来同步梯度和缓存。更具体地讲,DDP 对 model.parameters() 的每个参数创建了梯度钩子,在反向传播过程中对应梯度完成计算时这些钩子将被触发。然后 DDP 使用这些信号来触发跨进程的梯度同步。你可以参考 DDP 设计笔记来了解更多的细节。
DDP 的推荐用法是对每个模型副本都创建一个进程,每个模型副本可以使用多个 device。DDP 进程能够在单个机器或者多台机器下部署,但 GPU 设备不能在多个进程间共享。这个教程从一个基本的 DDP 使用案例开始,逐步引入更多的高级案例,如 checkpoint 和融合模型并行到 DDP 数据并行。
DataParallel 和 DistributedDataParallel 的区别#
在正式进入教程前,我们先解释为什么要使用更复杂一点的 DistributedDataParallel 而不是 DataParallel。
- 第一,
DataParallel是单进程多线程的,只能在一个机器上工作。DistributedDataParallel则是多进程的,且能够在单机或多机上部署训练。即使是在单机上,DataParallel通常也会慢于DistributedDataParallel,因为跨进程的 GIL、模型分发以及额外的输入分发、输出汇总。 - 回忆先前的教程 ↗,如果你的模型太大,那你可能要使用模型并行来在多个 GPU 上训练。
DistributedDataParallel能够适配模型并行,但DataParallel不行。当在 DDP 中使用模型并行时,每个 DDP 进程将使用模型并行,每个进程还将使用数据并行。 - 如果你的模型需要跨机器训练,或者你的使用情景不能归纳到数据并行范式,请查看 RPC API ↗ 来了解更加通用的分布式训练支持。
基本使用样例#
要使用 DDP,你要先正确设置一个进程组(process group)。更多的细节请参阅结合 Pytorch 编写分布式应用 ↗。
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
# On Windows platform, the torch.distributed package only
# supports Gloo backend, FileStore and TcpStore.
# For FileStore, set init_method parameter in init_process_group
# to a local file. Example as follow:
# init_method="file:///f:/libtmp/some_file"
# dist.init_process_group(
# "gloo",
# rank=rank,
# init_method=init_method,
# world_size=world_size)
# For TcpStore, same way as on Linux.
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()现在,我们可以创建一个简单的深度学习模块了,然后使用 DDP 包装这个模块,在随便给它一些输入。注意,DDP 在构造时会把 rank 0 进程的模型状态广播到其他进程,所以你不需要考虑不同 DDP 进程的模型的初始值是否一致。
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def run_demo(demo_fn, world_size):
mp.spawn(demo_fn,
args=(world_size,),
nprocs=world_size,
join=True)可以看到,DDP 封装了底层的分布式通信细节,为我们提供了简洁的 API。梯度同步的通信在反向传播时进行,并覆盖原有的反向传播计算过程。当 backward() 返回时,param.grad 已经是同步的梯度张量了。在这个简单的例子中,DDP 只需要了了几行就能设置进程组。当在更复杂的情况下使用 DDP 时,需要注意一些警告。
处理进程异步问题#
在 DDP 中,构造函数、前向传播、反向传播都是分布式下的同步点。不同进程应该启动相同数量的同步点,并且以相同的顺序到达这些同步点,还应该在基本相同的时间到达这些同步点。否则,更快的进程可能更快到达同步点并超时等待更慢的进程。所以,用户需要负责平衡不同进程间的工作任务。某些时候,进程速度倾斜可能无法避免,比如网络出现延迟、资源竞争、抑或是一些不好预料的负载峰值。为了避免超时,请确保创建进程组时设置的 timeout 参数合理。
保存和读取 checkpoint#
一个常见的操作是使用 torch.save 和 torch.load 来保存、读取网络等模块的中间状态。在 DDP 下,一个优化是只让一个进程保存模型,然后在剩下的进程读取。如果使用这个优化,我们需要确保没有进程在保存前读取状态。另外,在读取模块状态时,你还需要提供合适的 map_location 参数,来防止进程误用其他进程的设备。如果 map_location 没有设置,torch.load 会先把数据读入 CPU,然后复制到它原来的设备里,这可能导致所有进程使用同一块设备。对于更复杂的错误恢复,请阅读 TorchElastic ↗。
def demo_checkpoint(rank, world_size):
print(f"Running DDP checkpoint example on rank {rank}.")
setup(rank, world_size)
model = ToyModel().to(rank)
ddp_model = DDP(model, device_ids=[rank])
CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"
if rank == 0:
# All processes should see same parameters as they all start from same
# random parameters and gradients are synchronized in backward passes.
# Therefore, saving it in one process is sufficient.
torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)
# Use a barrier() to make sure that process 1 loads the model after process
# 0 saves it.
dist.barrier()
# configure map_location properly
map_location = {'cuda:%d' % 0: 'cuda:%d' % rank}
ddp_model.load_state_dict(
torch.load(CHECKPOINT_PATH, map_location=map_location))
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
# Not necessary to use a dist.barrier() to guard the file deletion below
# as the AllReduce ops in the backward pass of DDP already served as
# a synchronization.
if rank == 0:
os.remove(CHECKPOINT_PATH)
cleanup()同时使用 DDP 和模型并行#
DDP 也能和多 GPU 模型同时使用。DDP 封装的多 GPU 模型在大数据、大模型的情况下很有用。
class ToyMpModel(nn.Module):
def __init__(self, dev0, dev1):
super(ToyMpModel, self).__init__()
self.dev0 = dev0
self.dev1 = dev1
self.net1 = torch.nn.Linear(10, 10).to(dev0)
self.relu = torch.nn.ReLU()
self.net2 = torch.nn.Linear(10, 5).to(dev1)
def forward(self, x):
x = x.to(self.dev0)
x = self.relu(self.net1(x))
x = x.to(self.dev1)
return self.net2(x)当把一个多 GPU 模型传递给 DDP 时,你不应设置 device_ids 和 output_device。输入和输出数据应存放在合适的设备上,这一步应由应用或者模型的 forward 方法完成。
def demo_model_parallel(rank, world_size):
print(f"Running DDP with model parallel example on rank {rank}.")
setup(rank, world_size)
# setup mp_model and devices for this process
dev0 = (rank * 2) % world_size
dev1 = (rank * 2 + 1) % world_size
mp_model = ToyMpModel(dev0, dev1)
ddp_mp_model = DDP(mp_model)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)
optimizer.zero_grad()
# outputs will be on dev1
outputs = ddp_mp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(dev1)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
if __name__ == "__main__":
n_gpus = torch.cuda.device_count()
assert n_gpus >= 2, f"Requires at least 2 GPUs to run, but got {n_gpus}"
world_size = n_gpus
run_demo(demo_basic, world_size)
run_demo(demo_checkpoint, world_size)
run_demo(demo_model_parallel, world_size)使用 torch.distributed.run/torchrun 初始化 DDP#
我们可以使用 Pytorch Elastic 来初始化 DDP 代码,这能让我们的工作更加简单。我们还是使用上文的简单模型,然后创建一个名为 elastic_ddp.py 的文件。
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
model = ToyModel().to(device_id)
ddp_model = DDP(model, device_ids=[device_id])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(device_id)
loss_fn(outputs, labels).backward()
optimizer.step()
if __name__ == "__main__":
demo_basic()然后,我们在所有节点上运行 torch elastic/torchrun 命令来初始化 DDP 任务:
torchrun --nnodes=2 --nproc_per_node=8 --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=$MASTER_ADDR:29400 elastic_ddp.py我们在两个机器上运行 DDP 脚本,每个机器有 8 个进程,这意味着我们同时在 16 个 GPU 上运行模型。注意 $MASTER_ADDR 在所有节点上必须相同。
torchrun 将启动 8 个进程,并启动 elastic_ddp.py 在每个节点上,不过用户同时也需要使用集群管理工具(比如 slurm)来在两个节点上运行命令。
例如,在一个 SLURM 集群上,我们可以使用这样的命令来设置 MASTER_ADDR:
export MASTER_ADDR=$(scontrol show hostname ${SLURM_NODELIST} | head -n 1)然后我们可以直接把这些命令保存成脚本,然后使用 SLURM 命令来同时在集群上运行:srun --nodes=2 ./torchrun_script.sh。当然,这只是一个简单的例子,你可以使用自己的集群管理工具来启动任务。
使用经验#
各位读者需要意识到,在 DDP 里,每个进程都有着自己的模型、自己的输入、自己的输出、自己的 loss,DDP 只不过是在各个进程间维护了一致的模型初始状态和梯度,这些进程除此之外几乎是相互独立的。所以如果你想在 DDP 后做事,不但需要考虑是否要像 checkpoint 一样指定一个唯一的 rank 来做这件事,还需要自行同步所有进程上的数据。这涉及到分布式编程的常见问题,以下基本上都是在处理这些情况。好在 Pytorch 提供了丰富的分布式编程 API,我们得以简化很多操作。
后端的选择#
在初始化进程组的时候需要选择后端,这个后端的参数一般可以选择 nccl,如果要使用 CPU 训练的话,可以选择 gloo。
数据获取及 batch size#
第一个需要注意的是,DDP 下的 batch size 是对每一个进程设置的,而不是总数。所以如果需要设置 batch_size 为 ,你可能需要将其除以进程数,以保证梯度同步后是正确的。
第二个是在 DDP 中创建 DataLoader 的正确方法。DDP 中不存在输入的广播步骤,这意味着你必须从一开始就在不同的进程给模型使用不同的数据。为了达到这一点,可以使用 Pytorch 提供的 DistributedSampler。
# train_dataset
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset, shuffle=True, drop_last=True)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, sampler=train_sampler, pin_memory=True)在每个 epoch 中,在进入 dataloader 的迭代器前需要执行 train_sampler.set_epoch(epoch) 来让 shuffle 正常工作。
validation 阶段不需要这项操作。虽然会导致所有进程跑一遍所有数据,但使用该 sampler 可能会导致数据被截断(先要平分到进程,而后平分到 batch)。
指标统计#
不但 checkpoint 需要考虑不同进程间的同步问题,指标统计显然也是必要的。
对于 loss,可以这样做:
loss = loss.clone().detach()
loss_mean = dist.reduce(loss, rank=0) / dist.get_world_size()
if dist.get_rank() == 0:
# collect results into rank0
print(f"epoch: {epoch}, loss: {loss_mean} ")BatchNorm 层#
显然,由于 batch size 被按照进程大小切分,直接在每个进程里各玩各的 BatchNorm 是不合适的。为了在多进程间同步,你需要在 DDP 之前:
model = nn.SyncBatchNorm.convert_sync_batchnorm(model)随机数种子#
你需要考虑自己是否需要多个进程的随机数种子一致。必要的时候,使用 rank 来为不同进程设置不同的随机数种子。
random.seed(seed + dist.get_rank())
np.random.seed(seed + dist.get_rank())
torch.manual_seed(seed + dist.get_rank())
# 下面两行能维持最大的可复现,但会拖慢速度
# cudnn.deterministic = True
# cudnn.benchmark = False另外不仅 DDP 的分布式训练会导致随机数种子的问题, DataLoader 中也有同类问题. 虽然 Pytorch 正确处理了自己的 seed, 但是不代表你也是, 例如如果你在数据读取时使用了 numpy 的随机数, 那就需要自行给不同进程设置不同的 numpy seed.
Footnotes#
-
对于用户(人、代码)「透明」,意味着该组件的介入不会对它们的现状产生任何影响,它们不用也不会察觉到该组件的存在。就算阿卡林坐在你前桌也不会挡住你看黑板,大概是这意思。 ↩